Cárdenas, Tabasco.- Windows 10 ofrece la posibilidad de instalar un módulo de Linux para ejecutar en modo nativo aplicaciones Linux y es posible programar en Linux mientras se trabaja con Windows, así como ejecutar aplicaciones graficas de Linux en Windows sin requerir una maquina virtual. ¿Cómo hacerlo?, bueno seré lo más simple posible porque se que a la mayoría no nos gusta perder tiempo leyendo cosas innecesarias.
Como primer paso debemos tener instalado el componente de Linux en Windows y una vez que lo tengamos habilitado deberemos de abrir una sesiónde Power Shell en la cual introducirás el siguiente comando:
wsl --install
Esta instrucción instalará por defecto una versión de ubuntu Linux en nuestro entorno WSL. Como paso final nos solicitará establecer un nombre de usuario y una contraseña para ubuntu Linux.
Este entorno tiene preinstalado el Python 3, git tambien esta preinstalado en el sistemaLinux, por lo que no requeriremos instalar el lenguaje, ni el git, solo actualizar el sistema u las librerias del mismo con los siguientes comandos:
Para actualizar el sistema teclear
sudo apt update
Para obtener la última versión de todas las aplicaciones instaladas teclear
sudo apt upgrade -y
Para instalar el gestor de paquetes pip de python3 deberemos teclear
sudo apt install -y python3-pip
para manipular datos instalaremos la libreria pandas (misma que cargará las librerias numpy y matplotlib entre otras muchas), por lo general con esta libreria podemos hacer casí todo lo básico de trabajo con datos, para ello teclearemos
sudo apt install python3-pandas
Para trabajar con un ambiente integrado (IDE) nativo de Linux instale el paquete spyder tecleando
sudo apt install python3-spyder
finalizada la instalación de estos paquetes bastará con teclear en la línea de comandos "spyder" y podremos ver la aplicación que nos permitirá programar en Python desde ubuntu Linux.
Hecho esto podemos salir de spyder y cerrar nuestra sesión de Power Shell. para entrar al entorno linux desde Windows deberemos seguri cualquiera de los siguientes pasos:
Abrir una sesión de Power Shell y teclear en la línea de comandos
wsl
y obtendremos la siguiente línea de comandos de Linux dentro de la consola de powershell

Buscar WSL en el menú de inicio de Windows y hacer clic en el icono. Hecho esto obtendremos la siguiente pantalla de línea de comandos con una bienvenida genérica.

Al teclear spyder en la línea de comandos podremos ver la pantalla de inicio del entorno.

Y posteriormente se desplegará el IDE de spyder en su versión más reciente compatible con el ubuntu Linux.
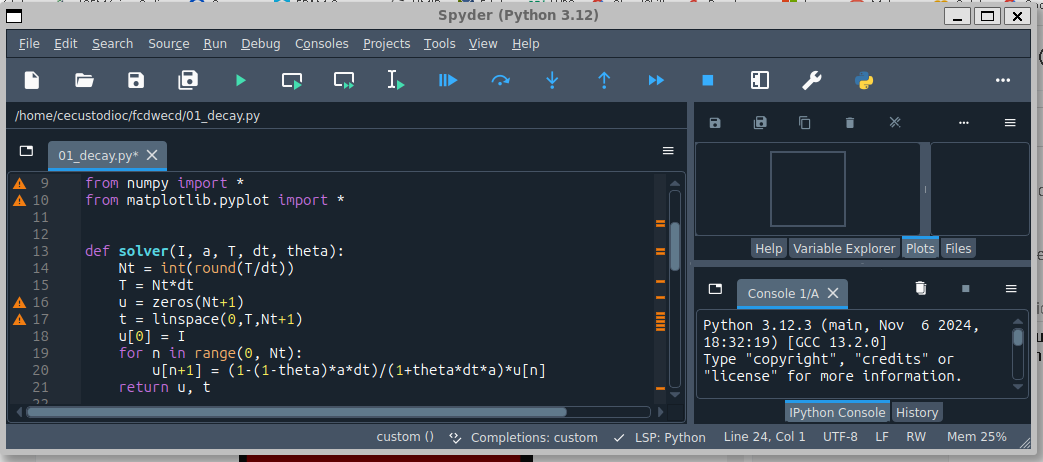
Podemos observar que la interfaz de la ventana es un poco diferente a la de las aplicaciones de Windows, esto se debe a que es una aplicación gráfica de ubuntu Linux ejecutandose en el subsistema Linux de Windows.
La otra opción para acceder a ubuntu Linux es buscar su icono en el menú de Windows y hacer clic sobre el mismo, así entraremos directo a la línea de comandos de ubuntu Linux sin la pantalla de bienvenida antes mencionada.

Y en el caso de la aplicación spyder podremos ver que en el grupo del ubuntu Linux se encuentra un icono para acceder directamente al IDE sin pasar por la línea de comandos, la forma en que decidamos acceder a la herramienta y el ambiente de programación integrado ya dependerá de nuestra preferencia.
Por lo pronto tienes todo lo necesario para empezar a programar con Python en ubuntu Linux, desde tu Windows 10 en tu computadora habitual, sin tener que lidiar con maquinas virtuales.
Espero te sea de utilidad lo aquí expuesto y facilite el desarrollo de tus actividades cotidianas con python en ubuntu Linux desde tu computadora con windows.
Quizá esto sea el inicio de la intercompatibilidad entre sistemas operativos y la transparecia de aplicaciones en las computadoras personales como lo tenemos en Internet.








")


")

